 快捷导航
快捷导航
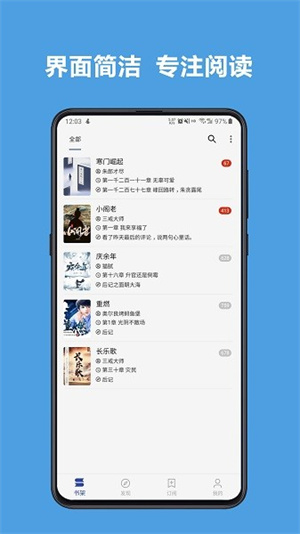
阅读app官方版是一可以免费阅读海量小说资源的网站,现在想要完整的看完一本小说得要花大几百,而且有些作者越到后面越水,还有可能太监,这就让很多用户们的钱直接打了水漂。这款软件可以让用户们不需要担心这些,1可以直接免费观看,而且还有多种书源可以选择,这个书源没了,那就换一个,总有一个有资源。
阅读app官方版内没有任何的广告,开屏广告和界面广告全部没有,让用户可以体验到最佳的体验。软件内拥有各大小说平台的热门冷门小说资源,用户们可以在平台上找到自己喜欢看的小说后,再在这里搜索资源进行观看,软件是完全免费的,也不需要观看广告。
开源阅读
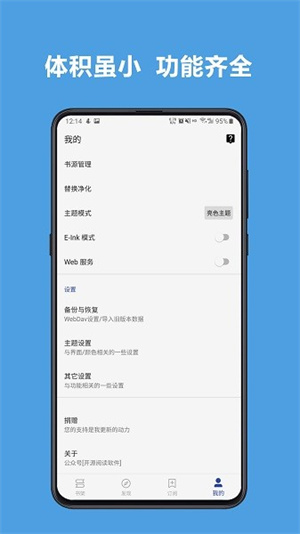
免费的开源阅读,可以自行设置规则抓取网页数据。
书源规则
这里的书源功能可以由用户自己定义,这样找书会更容易。
海量书源
可以轻松使用网络导入书源,书源多到可以找到任何一本书。
内容净化
支持相关内容替换,阅读净化内容后无广告。
翻页模式
支持叠加、模拟等多种阅读模式,自动阅读和释放双手操作。
1、简洁无广告
2、可添加书源
3、可听有声书
4、永久免费哦
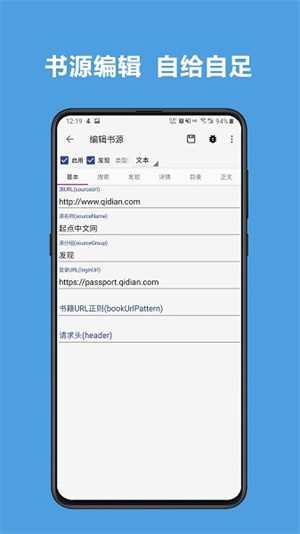
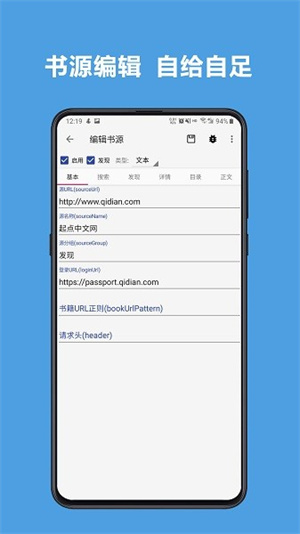
1、自定义书源,自己设置规则,抓取网页数据,规则简单易懂,软件内有规则说明。
2、列表书架,网格书架自由切换。
3、书源规则支持搜索及发现,所有找书看书功能全部自定义,找书更方便。
4、支持替换净化,去除广告替换内容很方便。
5、支持本地TXT、EPUB阅读,手动浏览,智能扫描。
6、支持高度自定义阅读界面,切换字体、颜色、背景、行距、段距、加粗、简繁转换等。
7、支持多种翻页模式,覆盖、仿真、滑动、滚动等。
8、软件开源,持续优化,无广告。
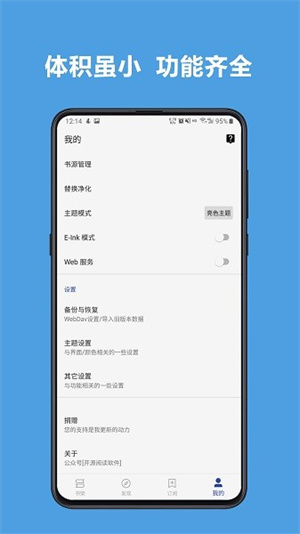
新建Read文件夹:
1、书架界面(也就是打开应用后的第一个界面)最右上角三个点图标,然后点击添加本地。
2、此时会弹出一个“选择文件夹”,我们使用“系统文件夹选择器”
3、请新建一个名为Read的文件夹,当然您也可以凭自己喜好命名。
4、选择 Read 文件夹,并点击使用此文件夹 ,系统会提示允许阅读访问Read中的文件吗,我们点击允许。
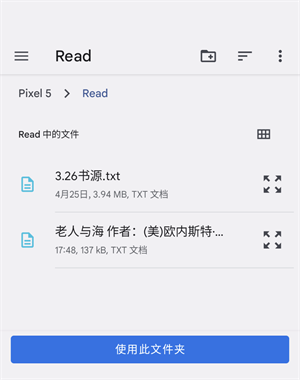
添加小说到书架:
1、首先您需要把小说文本文件存放在Read文件夹里。
2、在阅读添加本地的界面,勾选您要添加的小说。
3、最后点击右下方的“放入书架”,完成。
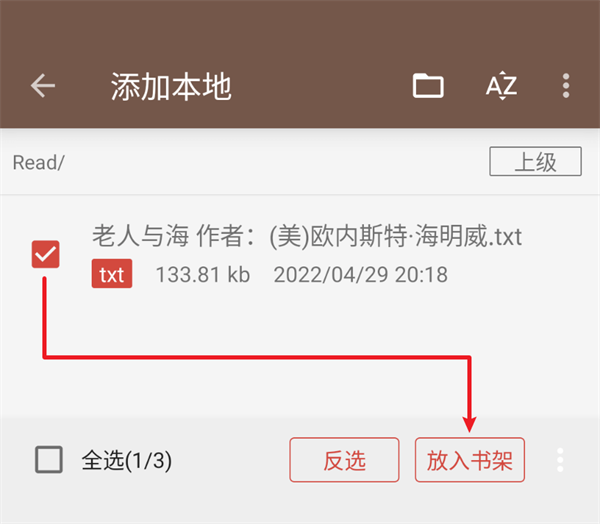
本地导入书源:
1、添加书源文件到Read文件夹。
2、导航栏“我的”界面,进入“书源管理”。
3、点击右上角三个点的图标,选择本地导入 。
4、在系统文件选择器里,点击您要添加的书源文件。
5、加载完成后,勾选书源或直接全选后确定,完成。
网络导入书源:
1、导航栏 我的 界面,进入书源管理 。
2、点击右上角三个点的图标,选择网络导入。
3、粘贴书源网址后点击确定。
4、加载完成后,勾选书源或直接全选后确定,完成。
友情提醒:
一般书源分两种导入情况,本地文件和网络链接。书源格式后缀有 txt、json ,其中json文件某些情况下无法导入,需要修改后缀为txt格式才可导入
1、在本站下载好阅读后安装。
2、打开软件,在左上角三横线出点击,打开菜单选项,找到书源管理。
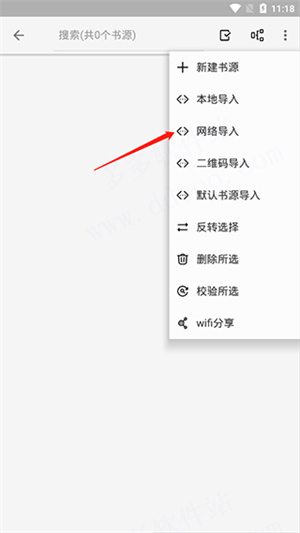
3、打开后再右上角点击三个小点找到里面的网络导入。
4、在打开的窗口中粘贴进下文任意一个书源,点击确认即可。
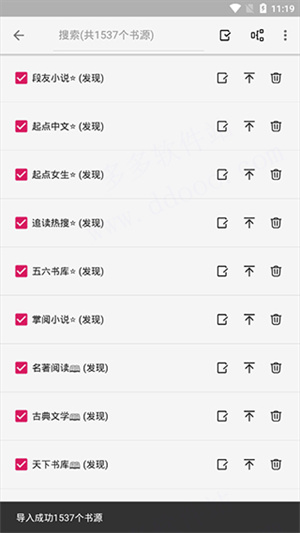
5、软件会自动导入该网站收录的书源。

6、然后我们返回软件首页,点击搜索即可搜索小说。
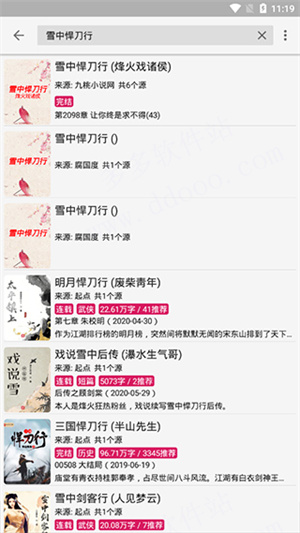
7、可以看到小说是完全免费的,全文都可以阅读。

1、书源规则基于HTML标记,如class,id,tag等
2、想要写规则先要打开网页源代码,在里面找到想要获取内容对应的标签,
3、Chrome可以在网页上右击点击检查可以方便的查看标签
4、基本写法
@为分隔符,用来分隔获取规则
每段规则可分为3段
第一段是类型,如class,id,tag等, children获取所有子标签,不需要第二段和第三段
第二段是名称,
第三段是位置,class,tag会获取到多个,所以要加位置,id类型不要加
5、如不加位置会获取所有
!是排除,有些位置不符合需要排除用!,后面的序号用:隔开,%为最后一个
@的最后一段为获取内容,如text,textNodes,href,src,html等
6、如果有不同网页的规则可以用 | 或 & 分隔,|会以第一个取到值的为准, & 会合并所有规则取到的值
7、如需要正则替换在最后加上 #正则表达式
8、例:class.odd.0@tag.a.0@text|tag.dd.0@tag.h1@text#全文阅读
9、例:class.odd.0@tag.a.0@text&tag.dd.0@tag.h1@text#全文阅读
应用信息
热门推荐
更多版本

阅读app解除书源版17.96MB新闻阅读v3.23.110211
查看
阅读7000书源一键导入版17.96MB新闻阅读v3.25
查看
阅读app下载正版17.75MB新闻阅读v3.23.112523
查看
阅读app的4000个书源版17.96MB新闻阅读v3.25
查看
开源阅读软件10000个书源版17.96MB新闻阅读v3.25
查看实时热词
评分及评论
























点击星星用来评分