 快捷导航
快捷导航
系统:PC
日期:2021-10-26
类别:行业软件
版本:v3.7.2
Weka是一款功能十分强大的专业的数据挖掘工具,采用先进的算法进行处理,将数据采集预处理、评估方法等融为一体,不仅提高了数据的精确性,还节省了时间、成本等各项指标,极大地提高了效率。
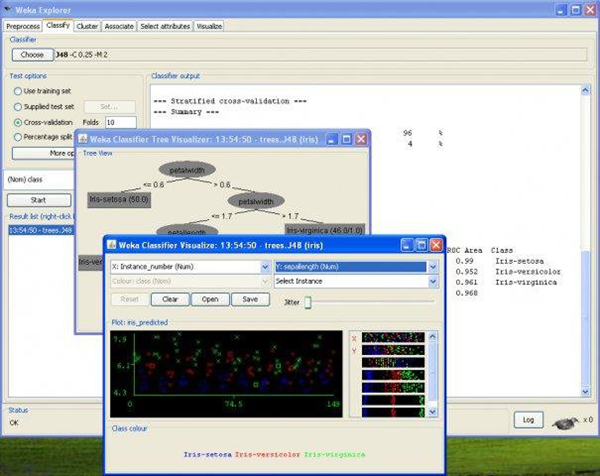
1、可以处理一个数据库的查询结果
2、weka软件支持相同功能的命令行,或是一种基于组件的知识流接口
3、集成自己的算法甚至借鉴它的方法自己实现可视化工具都很简单
4、技术基于假设数据是以一种单个文件或关联的
5、使用Java的数据库链接能力可以访问SQL数据库
【原理与实现】
聚类分析中的“类”(cluster)和前面分类的“类”(class)是不同的,对cluster更加准确的翻译应该是“簇”。聚类的任务是把 所有的实例分配到若干的簇,使得同一个簇的实例聚集在一个簇中心的周围,它们之间距离的比较近;而不同簇实例之间的距离比较远。对于由数值型属性刻画的实 例来说,这个距离通常指欧氏距离。
【模型应用】
现在我们要用生成的模型对那些待预测的数据集进行预测了。注意待预测数据集和训练用数据集各个属性的设置必须是一致的。即使你没有待预测数据集的Class属性的值,你也要添加这个属性,可以将该属性在各实例上的值均设成缺失值。
在“Test Opion”中选择“Supplied test set”,并且“Set”成你要应用模型的数据集,这里是“bank-new.arff”文件。
现在,右键点击“Result list”中刚产生的那一项,选择“Re-evaluate model on current test set”。右边显示结果的区域中会增加一些内容,告诉你该模型应用在这个数据集上表现将如何。如果你的Class属性都是些缺失值,那这些内容是无意义 的,我们关注的是模型在新数据集上的预测值。
现在点击右键菜单中的“Visualize classifier errors”,将弹出一个新窗口显示一些有关预测误差的散点图。点击这个新窗口中的“Save”按钮,保存一个Arff文件。打开这个文件可以看到在倒 数第二个位置多了一个属性(predictedpep),这个属性上的值就是模型对每个实例的预测值。
【建模结果】
OK,选上“Cross-validation”并在“Folds”框填上“10”。点“Start”按钮开始让算法生成决策树模型。很快,用文 本表示的一棵决策树,以及对这个决策树的误差分析等等结果出现在右边的“Classifier output”中。同时左下的“Results list”出现了一个项目显示刚才的时间和算法名称。如果换一个模型或者换个参数,重新“Start”一次,则“Results list”又会多出一项。
1、在启动WEKA时,会弹出GUI选择器,让您选择使用WEKA和数据的四种方式。选择Explorer选项已经足够。
2、weka是基于java,用于数据挖掘和知识分析一个平台。从海量数据中发掘其背后隐藏的种种关系。
3、数据创建完成后,就可以开始创建我们的回归模型了。启动 WEKA,然后选择 Explorer。将会出现 Explorer 屏幕,其中 Preprocess 选项卡被选中。选择 Open File 按钮并选择在上一节中创建的 ARFF 文件。
热门推荐
相关应用
实时热词
评分及评论
是共享软件吗,用过的朋友冒个泡哈
支持一下!会分享给同学尝试一下
不愧高端制作,这样的完成度也能达到这样的水平
收藏了,以后都来这里下
我就收下了这份沉甸甸的心意。嘿嘿

贵州网院电脑版58.11MB教育学习v1.29
查看
23j909图集PDF免费下载43.4MB图形图像v1.0
查看
WPS Office2025破解版341.6MB办公软件v12.1.0.23542
查看
中国银行网银助手企业版官方版下载36.4MB硬件驱动v4.0.9.1
查看
IntelliJ IDEA2026破解版1.47GB编程开发v2026.1
查看
中国银行网银助手官方版下载36.4MB网络工具v4.0.9.1
查看
Office2024破解版3.1GB办公软件v16.0.17102
查看
造梦西游3修改器下载10.4MB杂类工具v12.0
查看
















点击星星用来评分