 快捷导航
快捷导航
系统:PC
日期:2025-10-23
类别:办公软件
版本:v18.3
SPSS Modeler18破解版是一款专业的在线科学数据学习软件,一款能够让用户可以在这里一站式数据准备、发现、预测分析、模型管理以及部署,让每一个数据都能成为资产一样快速变现,让用户可以在这里轻松管理数据信息。SPSS Modeler18破解版Crack有着好用的数据自动准备功能,在这里快速设置,这样就能自动转换最佳格式的数据。
SPSS Modeler18破解版可用于构建预测模型和进行高级数据分析,从多种模型上快速部署,让用户能够高效率完成机器的学习框架和模型。
1、访问各种类型的数据
借助SPSS Modeler,您可以使用各种分析技术访问数据源, 如数据仓库、数据库、Hadoop 分布或平面文件,以便从您 的数据中发现隐含的模式。这些统计技术使用历史数据来预 测当前状况或未来事件。这些统计技术还包括数据访问、数 据准备、数据建模和交互可视化功能。借助准备和建模自动 化流程,该产品适用于各种分析能力。
2、通过一系列技术拓宽您的分析范围
借助 SPSS Modeler,您的分析师可利用设计用于处理简单 的描述性分析问题、最复杂的优化问题以及这两者之间的一 切问题的单一平台,解决业务问题。SPSS Modeler 具有超 出当今分析师标准分析要求的功能。一系列模型以及自动建 模和数据准备、文本分析、实体分析和社交网络分析功能, 可以帮助您处理最复杂的问题。
3、一系列模型及算法
分类算法-根据历史数据和技术进行预测。分段算法-利用自动聚类、异常检测和聚类神经网络技术 将工作人员进行分组或检测不寻常的模式。关联算法-发现先验、CARMA 和序列关联性的关联、链 接或序列。时间系列和预测-随着时间的推移,利用统计建模技术生成一个或多个系列的预测。可扩展性与 R 编程语言-应用转型,用脚本进行分析, 并用 R 编程语言汇总或生成文本和图形输出。
4、数据准备和操作
SPSS Modeler 使数据准备自动化,以简化流程并帮助您确 保您的数据格式为便于分析的最好格式。自动化任务包括进 行分析数据和识别修复工具,筛选字段,必要时派生新属性, 并通过智能筛选技术提高性能。
5、自动数据建模
借助 SPSS Modeler 的自动建模功能,非分析师人员无需 专业技能即可迅速构建准确的模型。此外,先进的预测建 模功能可支持专业分析人员创建最复杂的流。
6、地理空间分析
借助 SPSS Modeler,您可探索与某个位置有关的各个数 据元素之间的关系并对您的数据进行地理空间分析,以发掘在图表或表格中不可见的洞察力。通过空间挖掘,您可 利用 ESRI shape file 文件轻松挖掘地理空间数据。通过分 析空间数据和非空间数据,可以提高整个模型的准确性, 且您可以获取对人员和事件的更深入洞察力。
1、导入文件。进入SPSS的主界面窗口后,我们切换到【文件】选项卡,使用其中的【打开、新建或导入数据】命令,导入用于创建神经网络的原始数据。
2、分析-神经网络。随后切换到【分析】选项卡,依次点击其下拉列表中的【神经网络-多层感知器】选项。
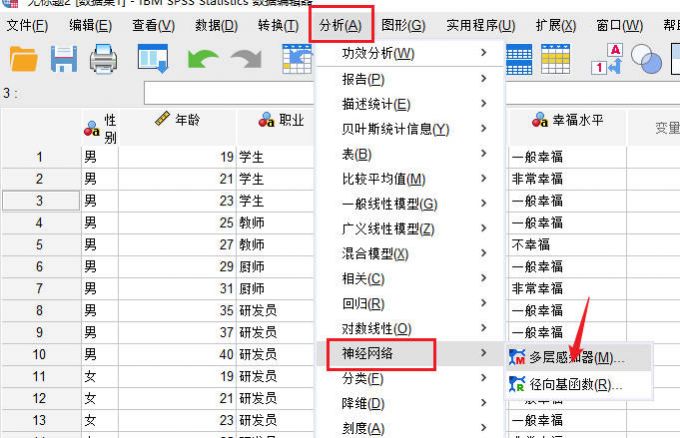
3、设置多层感知器。进入多层感知器的设置窗口后,我们按照数据类型,分别将【因变量、因子和协变量】拖拽到对应的目标选框。
4、设置分区。随后切换到【分区】选项卡,根据分区表格中对于神经网络的分区占比进行设置,主要包括【训练、检验和坚持】三项。
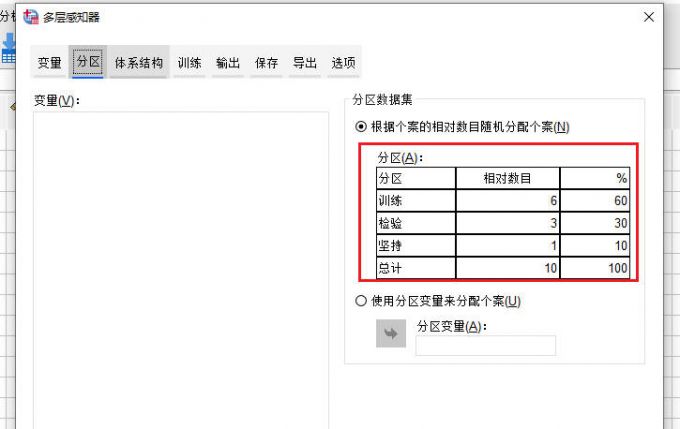
5、设置训练。切换到【训练】选项卡,我们可以设置训练类型,包括【批次、联机和小批次】;下方的算法优化方式包括【标度共轭梯度和梯度下降】。完成设置后,点击底部的【确定】命令即可开始进行神经网络创建。
任务 1: 创建项目
您需要一个项目来存储 SPSS Modeler 流程。 执行以下步骤以创建项目:
从 Cloud Pak for Data 导航菜单 导航菜单 ,选择项目 > 所有项目。
如果现有一个项目,请将其打开。
如果您没有现有项目,请单击 新建项目。
选择创建空项目。
输入项目的名称和可选描述。
单击创建。
任务 2:将数据集添加到项目
本教程使用样本数据集。 执行以下步骤以将样本数据集添加到项目:
下载 chronic_kidney_disease_full.csv 文件 (39 KB)。
下载地址:https://www.ibm.com/docs/zh/SSQNUZ_4.6.x/cpd/get-started/assets/chronic_kidney_disease_full.csv
将 chronic_kidney_disease_full.csv 文件添加到项目:
从项目中单击上传资产到项目图标 "将资产上载到项目" 图标。
在打开的侧面板中,浏览以选择 chronic_kidney_disease_full.csv 文件,然后单击 打开。 请停留在该页面,直至装入完成为止。
chronic_kidney_disease_full.csv 文件将作为数据资产添加到项目中。
从项目的 " 资产 " 页面中,打开 chronic_kidney_disease_full.csv 文件以预览数据。 有三个重要因素有助于预测慢性肾脏疾病,这些因素可作为这项分析的一部分: 试验对象的年龄,血清肌酐测试结果和糖尿病测试结果。 而该类数值表明患者是否曾被确诊为肾脏疾病。
单击导航跟踪中的项目名称以返回到 资产 选项卡。
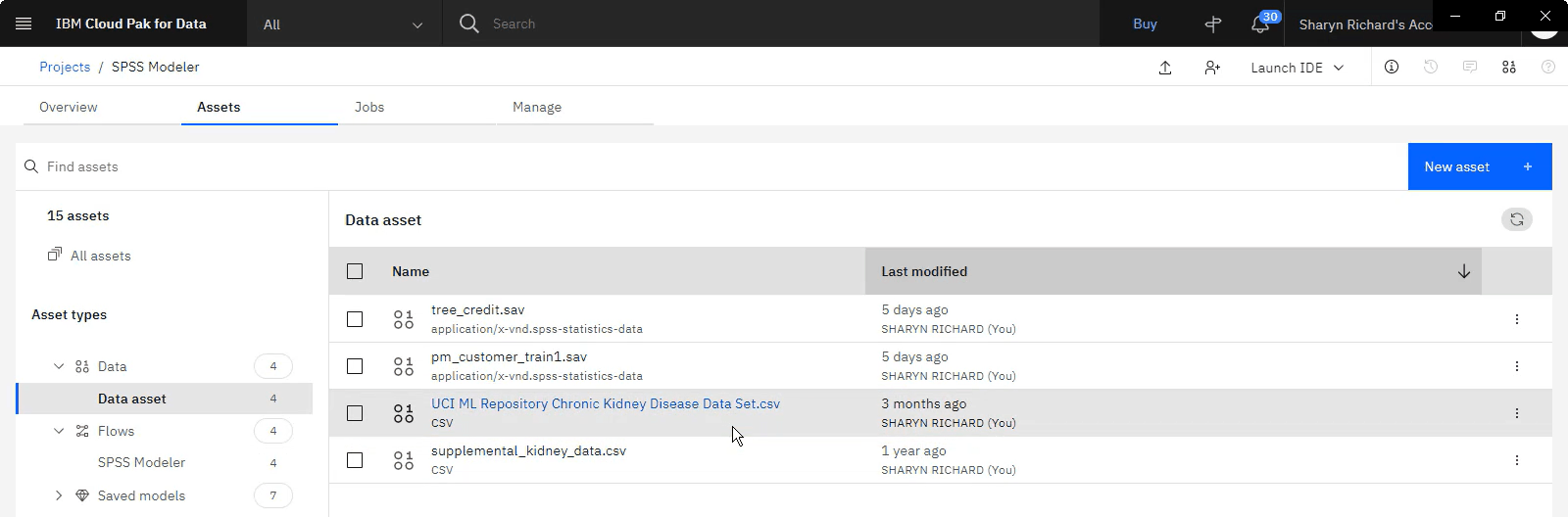
任务 3: 创建 SPSS Modeler 流程
遵循以下步骤在项目中创建 SPSS Modeler 流:
单击 新建资产,然后选择 Modeler 流程。
输入流的名称和描述。
单击创建。 这将打开将用于创建流的流编辑器。
任务 4:将节点添加到 SPSS Modeler 流程
装入数据后,必须变换数据。 通过将变换器和估计量拖到画布上并将其连接到数据源来创建简单流。 使用选用板中的以下节点:
数据资产: 从项目装入 csv 文件
分区: 将数据划分为训练和测试段
类型: 设置数据类型。 使用它将 class 字段指定为 target 类型。
C5.0: 分类算法
分析: 查看模型并检查其准确性
表: 预览具有预测的数据
执行以下步骤以创建流:
添加数据资产节点:
从 导入 部分中,将 数据资产 节点拖到画布上。
双击 数据资产 节点以选择数据集。
在打开的窗格中单击 更改数据资产 。
在打开的页面中选择 数据资产 。
选择 chronic_kidney_disease_full.csv。
单击确定。
查看数据资产属性。
单击保存。
添加分区节点:
从 字段操作 部分中,将 分区 节点拖到画布上。
将 数据资产 节点连接到 分区 节点。
双击 Partition 节点以查看其属性。 缺省分区将一半数据用于训练,另一半用于测试。
单击保存。
添加 "类型" 节点:
从 字段操作 部分中,将 类型 节点拖到画布上。
将 Partition 节点连接到 Type 节点。
双击 类型 节点以查看其属性。 "类型" 节点指定每个字段的测量级别。 此源数据文件使用四个不同的测量级别: "连续" , "分类" , "名义" , "有序" 和 "标志"。
搜索 class 字段。 对于每个字段,角色指示每个字段在建模中扮演的部分。 将 class 角色 更改为 目标 -要预测的字段。
单击保存。
添加 C5.0 分类算法节点:
从 建模 部分中,将 C5.0 节点拖到画布上。
将 Type 节点连接到 C5.0 节点。
双击 C5.0 节点以查看其属性。 缺省情况下, C5.0 算法会构建决策树。 C5.0 模型通过根据提供最大信息增益的字段拆分样本来工作。 第一次拆分所定义的每个子样本然后再拆分,通常基于不同的字段,过程会重复,直到子样本无法再拆分。 最后,将重新检查最低级别的拆分,并除去那些对模型的价值没有显着贡献的拆分。
选中 使用定制字段角色。
对于 目标,选择 class。
在 输入 部分中,单击 添加列。
选择 age, sc和 dm。
单击确定。
单击保存。
任务 5:运行 SPSS Modeler 流程并浏览模型详细信息
现在,您已设计流,请执行以下步骤来运行流,并检查树形图以查看决策点:
右键单击 C5.0 节点,然后选择 运行。 运行流会在画布上生成新的模型块。
右键单击模型块,然后选择 查看模型 以查看模型详细信息。
查看提供模型摘要的 模型信息 。
单击 排名靠前的决策规则。 表显示了一系列规则,这些规则用于根据不同输入字段的值将各个记录分配给子节点。
单击 特征重要性。 图表显示了每个预测变量在估计模型中的相对重要性。 由此可以看出,血清肌酐很容易是最重要的因素,糖尿病是下一个最重要的因素。
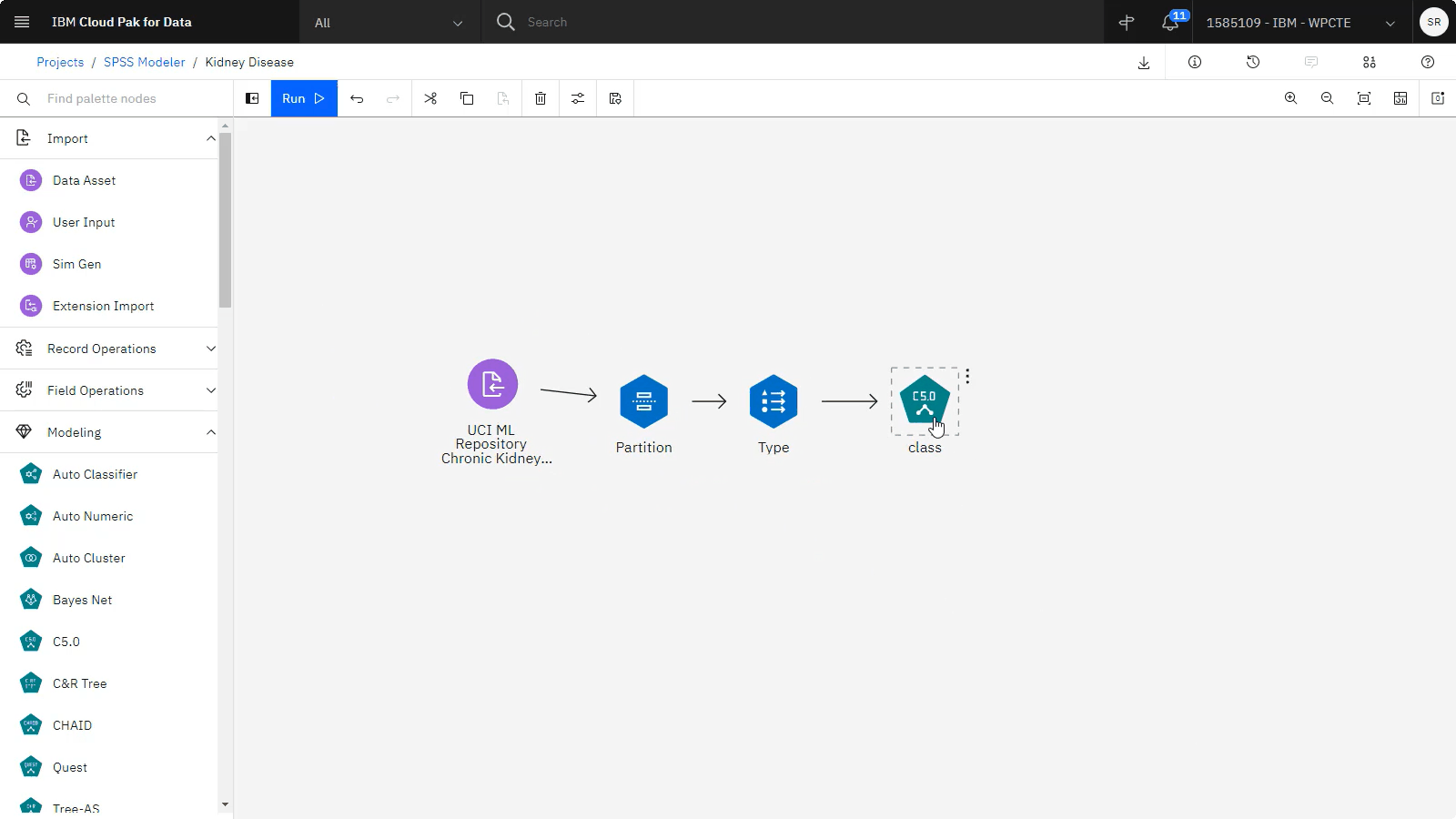
单击 树形图。 同一模型以树的形式显示,每个决策点都有一个节点。
选择 在分支上显示标签 选项。
将鼠标悬停在 节点 0 上,这将提供数据集中所有记录的摘要。 数据集中仅有不到 40% 的病例被归类为未确诊肾脏疾病。 树可以提供有关哪些因素可能负责的其他线索。
请注意,来自节点 0 的两个分支指示由 血清肌酐分割。
将鼠标悬停在 节点 6 上,这将显示血清肌酐大于 1.25的记录。 在这种情况下,其中 100% 的患者都有阳性肾脏疾病诊断。
将鼠标悬停在 节点 1 上,这将显示血清肌酐小于或等于 1.25的记录。 其中几乎 80% 的患者没有进行阳性肾脏疾病诊断,但几乎 20% 的血清肌酐较低的患者仍被诊断为肾脏疾病。
来自节点 1 的分支由 糖尿病拆分。 将鼠标悬停在 节点 2 上,这将显示低血清肌酐和已诊断的糖尿病患者。 这些患者 100% 也被诊断为肾脏疾病。
将鼠标悬停在 节点 3上。 对于血清肌酐低,无糖尿病的患者, 85% 以上未确诊肾脏病,但仍有 15% 的患者确诊肾脏病。
来自节点 3 的分支按最后一个有效因子 age进行拆分。 将鼠标悬停在 节点 4 上,以了解 75% 的低血清肌酐和无糖尿病的年轻患者有患肾脏疾病的风险。
将鼠标悬停在 节点 5上。 只有 11% 的 16 岁以上患者血清肌酐低,无糖尿病,有患肾脏疾病的风险。
使用面包屑导航可导航回模型。
任务 6:评估模型
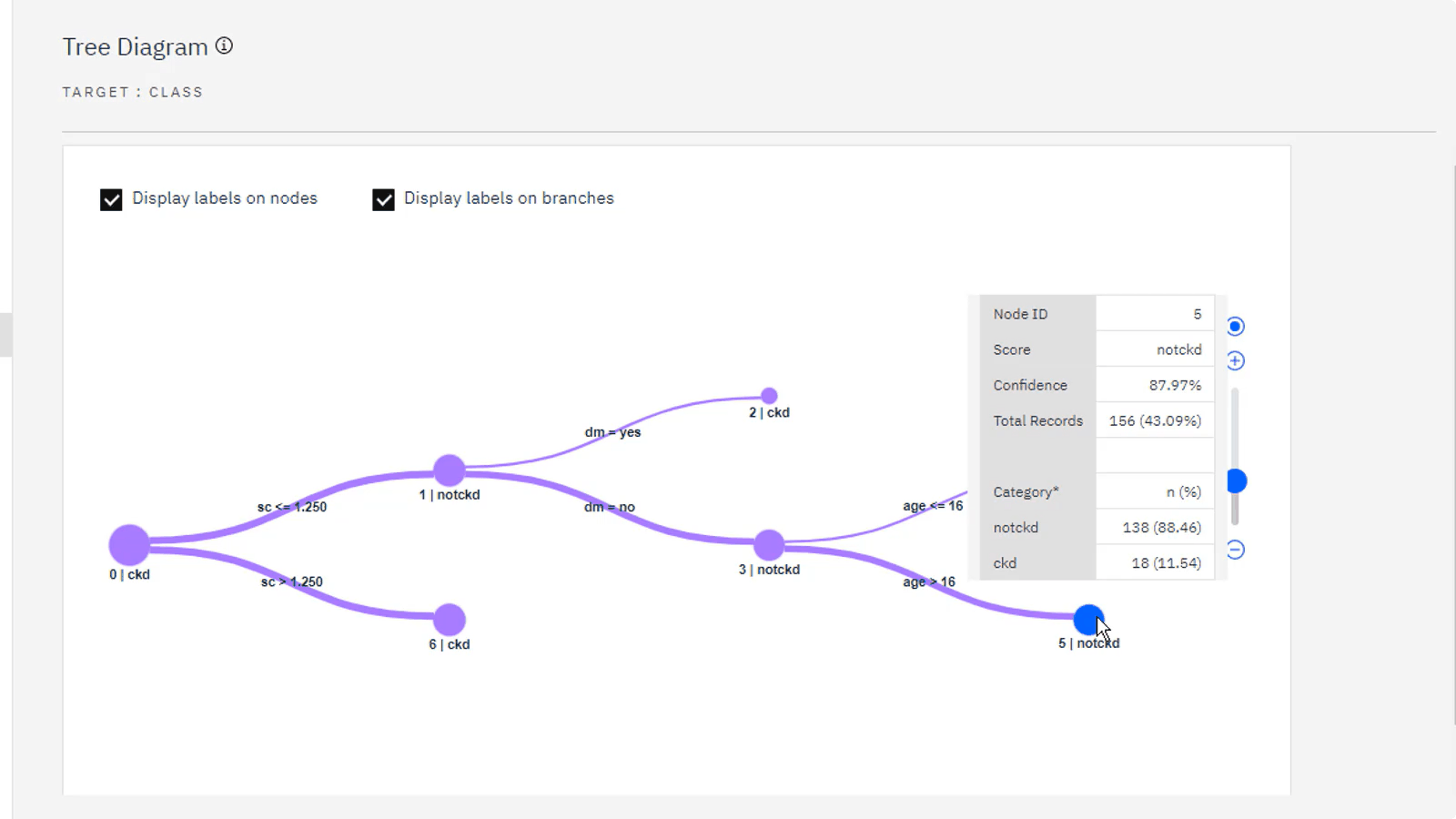
执行以下步骤以使用 "分析" 和 "表" 节点来评估模型:
从 输出 部分中,将 分析 节点拖到画布上。
将 模型 块连接到 分析 节点。
右键单击 分析 节点,然后选择 运行。
从 " 输出 " 面板中,打开 分析,显示模型正确预测了几乎 95% 的时间进行肾脏疾病诊断。 关闭 分析。
右键单击 分析 节点,然后选择 将分支另存为模型。
对于 模型名称,输入 Kidney Disease Analysis。
单击保存。
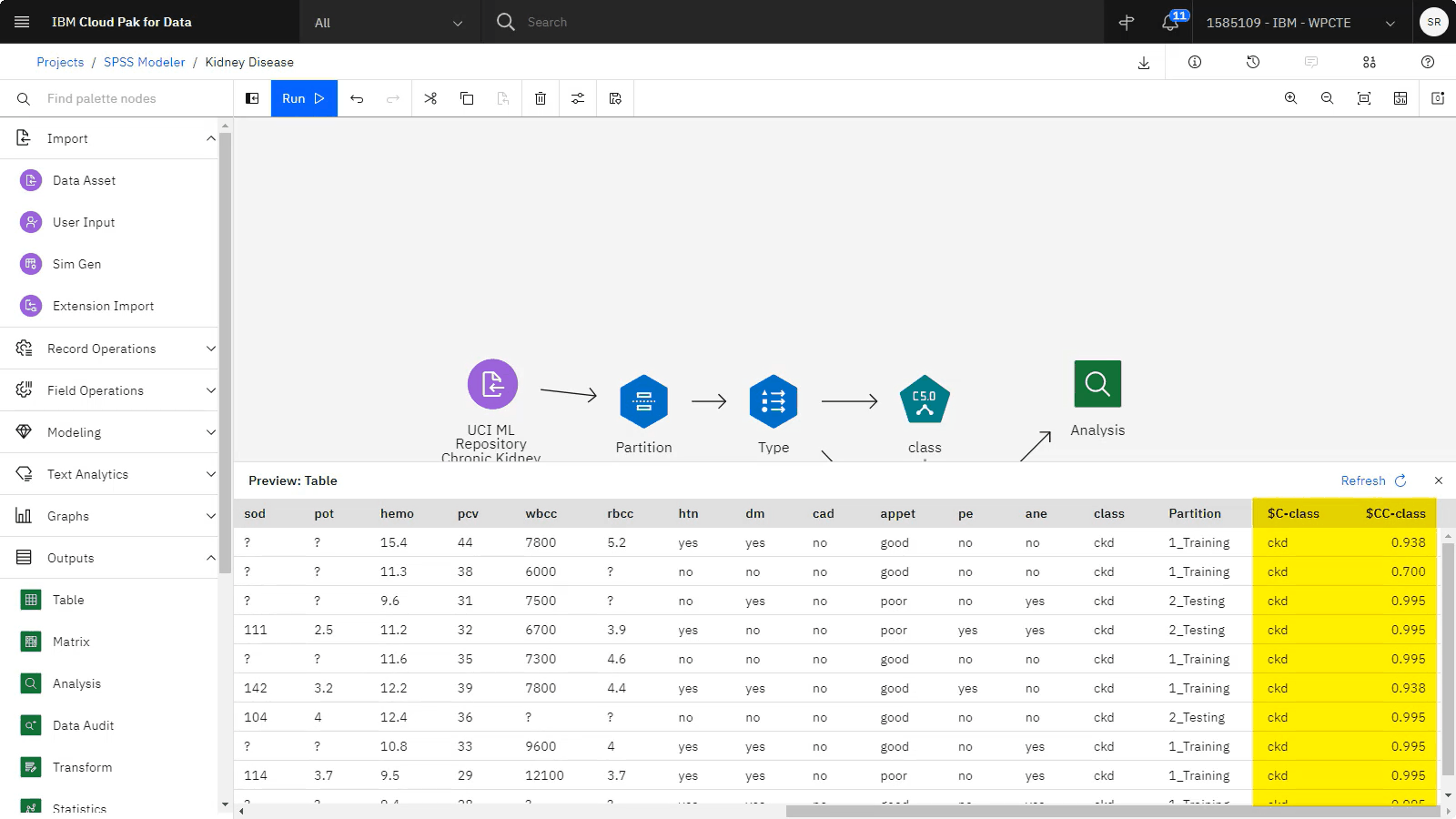
从 输出 部分中,将 表 节点拖到画布上。
将 模型 块连接到 表 节点。
右键单击 表 节点,然后选择 预览。
当 "预览" 显示时,滚动到最后两列。 $C-Class 列包含肾脏疾病的预测, $CC-Class 列指示该预测的置信度分数。
关闭 预览。
任务 7: 使用新数据部署和测试模型
最后,执行以下步骤以部署此模型并使用新数据预测结果。
返回到项目的 资产 选项卡。
滚动到 模型 部分,然后打开 肾脏疾病分析 模型。
单击提升。
选择现有部署空间。 如果您没有部署空间,那么可以创建新的部署空间:
提供空间名称。
单击创建。
单击关闭。
单击显示的 部署空间 链接,或者使用导航菜单浏览至 部署 以选择部署空间。
将鼠标悬停在模型上,然后单击 火箭 图标以部署模型。
选择 联机 作为 部署类型。
指定部署名称。
单击创建。
转至 部署 选项卡,然后等待部署模型。
部署完成后,单击部署名称以查看部署详细信息页面。
转至 测试 选项卡。 您可以通过两种方式从部署详细信息页面测试已部署模型:使用表单测试或使用 JSON 代码测试。
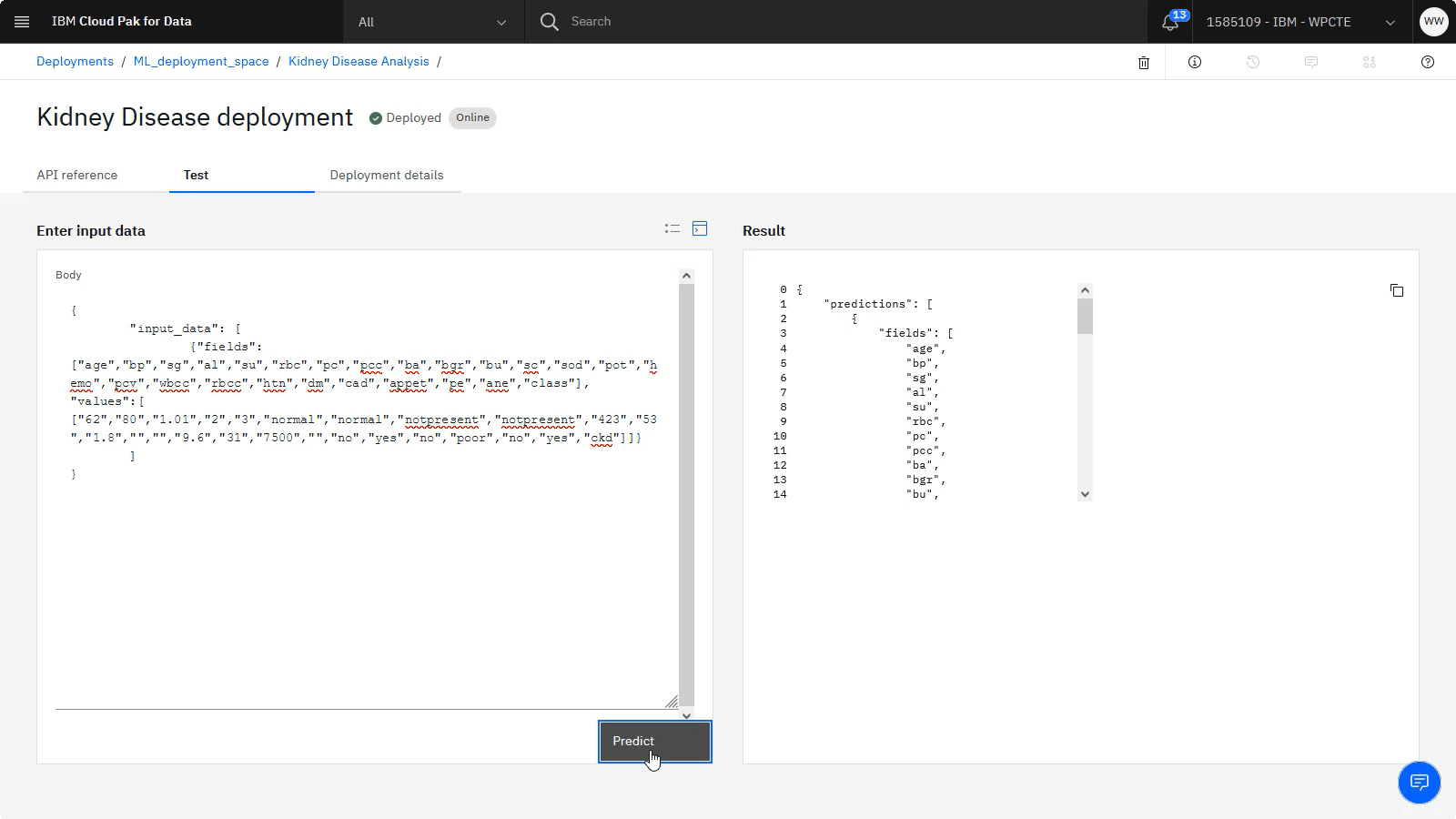
单击图标以以 JSON 格式提供输入数据,然后复制以下测试数据并将其粘贴到 JSON 文本的区域中:
{"input_data":[{"fields":["age","bp","sg","al","su","rbc","pc","pcc","ba","bgr","bu","sc","sod","pot","hemo","pcv","wbcc","rbcc","htn","dm","cad","appet","pe","ane","class"], "values":[["62","80","1.01","2","3","normal","normal","notpresent","notpresent","423","53","1.8","","","9.6","31","7500","","no","yes","no","poor","no","yes","ckd"]]}]}
单击 预测 以预测 62 岁的糖尿病患者和血清肌酐比率 1.8 是否可能诊断为肾脏疾病。 由此产生的预测表明,此患者进行肾脏疾病诊断的概率很高。
热门推荐
实时热词
评分及评论

贵州网院电脑版58.11MB教育学习v1.29
查看
23j909图集PDF免费下载43.4MB图形图像v1.0
查看
WPS Office2025破解版341.6MB办公软件v12.1.0.23542
查看
中国银行网银助手企业版官方版下载36.4MB硬件驱动v4.0.9.1
查看
IntelliJ IDEA2026破解版1.47GB编程开发v2026.1
查看
中国银行网银助手官方版下载36.4MB网络工具v4.0.9.1
查看
Office2024破解版3.1GB办公软件v16.0.17102
查看
造梦西游3修改器下载10.4MB杂类工具v12.0
查看














点击星星用来评分