 快捷导航
快捷导航
系统:PC
日期:2021-04-29
类别:编程开发
版本:v1.10.0
apache flink特别版是一款由Apache公司开发的开源大数据处理系统,我们可以使用这款软件来对数据流应用程序进行快速处理。而且apache flink中文版还能够根据电脑内存的性能来进行数据处理,从而在占用最少内存的情况下以最快速度完成数据处理工作。
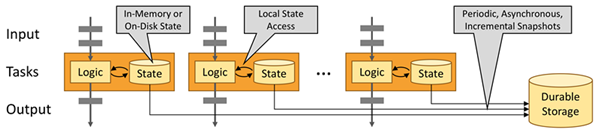
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
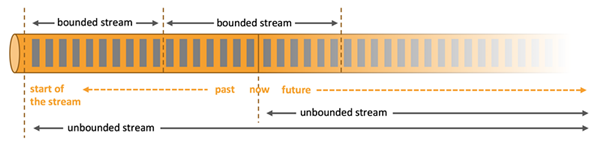
处理无界和有界数据
任何类型的数据都是作为事件流产生的。信用卡交易,传感器测量,机器日志或网站或移动应用程序上的用户交互,所有这些数据都作为流生成。
随处部署应用程序
Apache Flink是一个分布式系统,需要计算资源才能执行应用程序。Flink与所有常见的集群资源管理器(如Hadoop YARN,Apache Mesos和Kubernetes)集成,但也可以设置为作为独立集群运行。
以任何比例运行应用程序
Flink旨在以任何规模运行有状态流应用程序。应用程序可以并行化为数千个在集群中分布和同时执行的任务。因此,应用程序可以利用几乎无限量的CPU,主内存,磁盘和网络IO。而且,Flink可以轻松维护非常大的应用程序状态。其异步和增量检查点算法确保对处理延迟的影响最小,同时保证一次性状态一致性。
利用内存中的性能
有状态Flink应用程序针对本地状态访问进行了优化。任务状态始终保留在内存中,或者,如果状态大小超过可用内存,则保存在访问高效的磁盘上数据结构中。因此,任务通过访问本地(通常是内存中)状态来执行所有计算,从而产生非常低的处理延迟。Flink通过定期和异步检查本地状态到持久存储来保证在出现故障时的一次状态一致性。
数据流的运行流程
Flink程序在执行后被映射到流数据流,每个Flink数据流以一个或多个源(数据输入,例如消息队列或文件系统)开始,并以一个或多个接收器(数据输出,如消息队列、文件系统或数据库等)结束。Flink可以对流执行任意数量的变换,这些流可以被编排为有向无环数据流图,允许应用程序分支和合并数据流。
Flink的数据源和接收器
Flink提供现成的源和接收连接器,包括Apache Kafka、Amazon Kinesis、HDFS和Apache Cassandra等。
Flink程序可以作为集群内的分布式系统运行,也可以以独立模式或在YARN、Mesos、基于Docker的环境和其他资源管理框架下进行部署。
Flink的状态:检查点、保存点和容错机制
Flink检查点和容错:检查点是应用程序状态和源流中位置的自动异步快照。在发生故障的情况下,启用了检查点的Flink程序将在恢复时从上一个完成的检查点恢复处理,确保Flink在应用程序中保持一次性(exactly-once)状态语义。检查点机制暴露应用程序代码的接口,以便将外部系统包括在检查点机制中(如打开和提交数据库系统的事务)。
Flink保存点的机制是一种手动触发的检查点。用户可以生成保存点,停止正在运行的Flink程序,然后从流中的相同应用程序状态和位置恢复程序。 保存点可以在不丢失应用程序状态的情况下对Flink程序或Flink群集进行更新。
Flink的数据流API
Flink的数据流API支持有界或无界数据流上的转换(如过滤器、聚合和窗口函数),包含了20多种不同类型的转换,可以在Java和Scala中使用。
有状态流处理程序的一个简单Scala示例是从连续输入流发出字数并在5秒窗口中对数据进行分组的应用:Apache Beam - Flink Runner
Apache Beam“提供了一种高级统一编程模型,允许(开发人员)实现可在在任何执行引擎上运行批处理和流数据处理作业”。Apache Flink-on-Beam运行器是功能最丰富的、由Beam社区维护的能力矩阵。
data Artisans与Apache Flink社区一起,与Beam社区密切合作,开发了一个强大的Flink runner。
数据集API
Flink的数据集API支持对有界数据集进行转换(如过滤、映射、连接和分组),包含了20多种不同类型的转换。 该API可用于Java、Scala和实验性的Python API。Flink的数据集API在概念上与数据流API类似。
表API和SQL
Flink的表API是一种类似SQL的表达式语言,用于关系流和批处理,可以嵌入Flink的Java和Scala数据集和数据流API中。表API和SQL接口在关系表抽象上运行,可以从外部数据源或现有数据流和数据集创建表。表API支持关系运算符,如表上的选择、聚合和连接等。
也可以使用常规SQL查询表。表API提供了和SQL相同的功能,可以在同一程序中混合使用。将表转换回数据集或数据流时,由关系运算符和SQL查询定义的逻辑计划将使用Apache Calcite进行优化,并转换为数据集或数据流程序。
apache flink特别版如何用窗格来优化窗口?
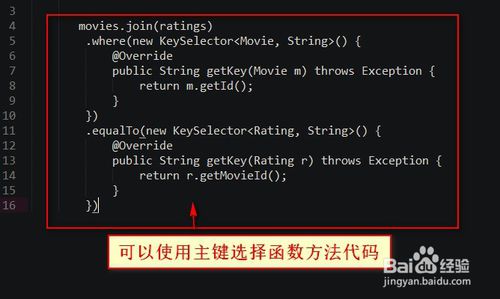
1.可以使用主键选择函数方法代码如下
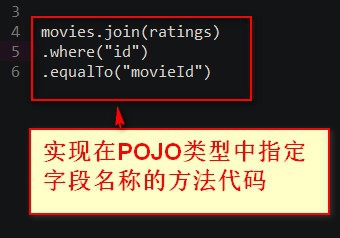
2.实现在POJO类型中指定字段名称的方法代码
3.使用的是Flink tuple类型--》那么只要简单地指定字段元组的位置--》可以被用作主键了代码如下
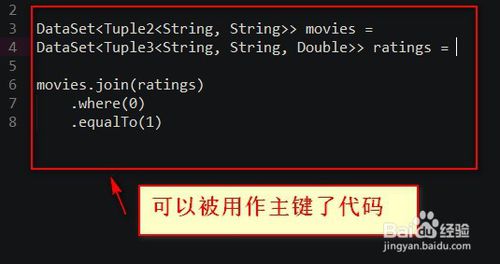
4.可读性的代码
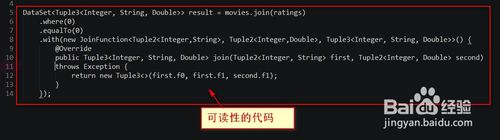
5.创建一个类--》该类需要继承TupleX类--》为类里面的这些字段实现getter和setter。
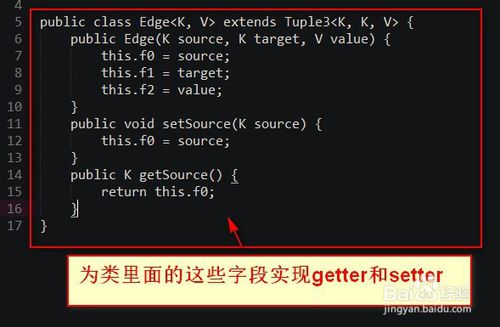
6.实现可以用来提高Flink应用程序性能的选项是当从用户定义的函数返回数据时使用可变对象代码如下
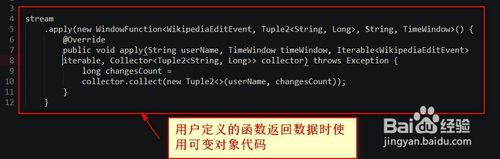
7.新建一个Tuple2类的实例--》因此增加了对垃圾收集器的压力--》解决这个问题的一种方法是反复使用相同的实例代码如下
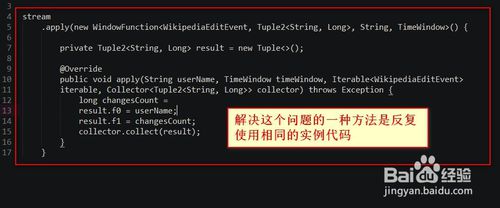
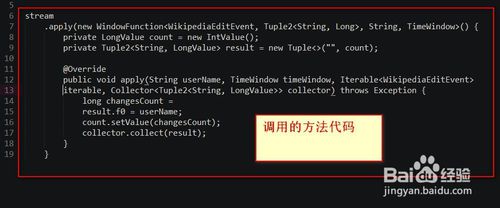
8.调用的方法代码如下
热门推荐
相关应用
实时热词
评分及评论
正好需要 ,感谢
支持,确实很好,就是没有快捷方式
这软件在我心中是10分!
高品质软件
真心好用,很满意。

贵州网院电脑版58.11MB教育学习v1.29
查看
23j909图集PDF免费下载43.4MB图形图像v1.0
查看
WPS Office2025破解版341.6MB办公软件v12.1.0.23542
查看
中国银行网银助手企业版官方版下载36.4MB硬件驱动v4.0.9.1
查看
IntelliJ IDEA2026破解版1.47GB编程开发v2026.1
查看
中国银行网银助手官方版下载36.4MB网络工具v4.0.9.1
查看
Office2024破解版3.1GB办公软件v16.0.17102
查看
造梦西游3修改器下载10.4MB杂类工具v12.0
查看














点击星星用来评分